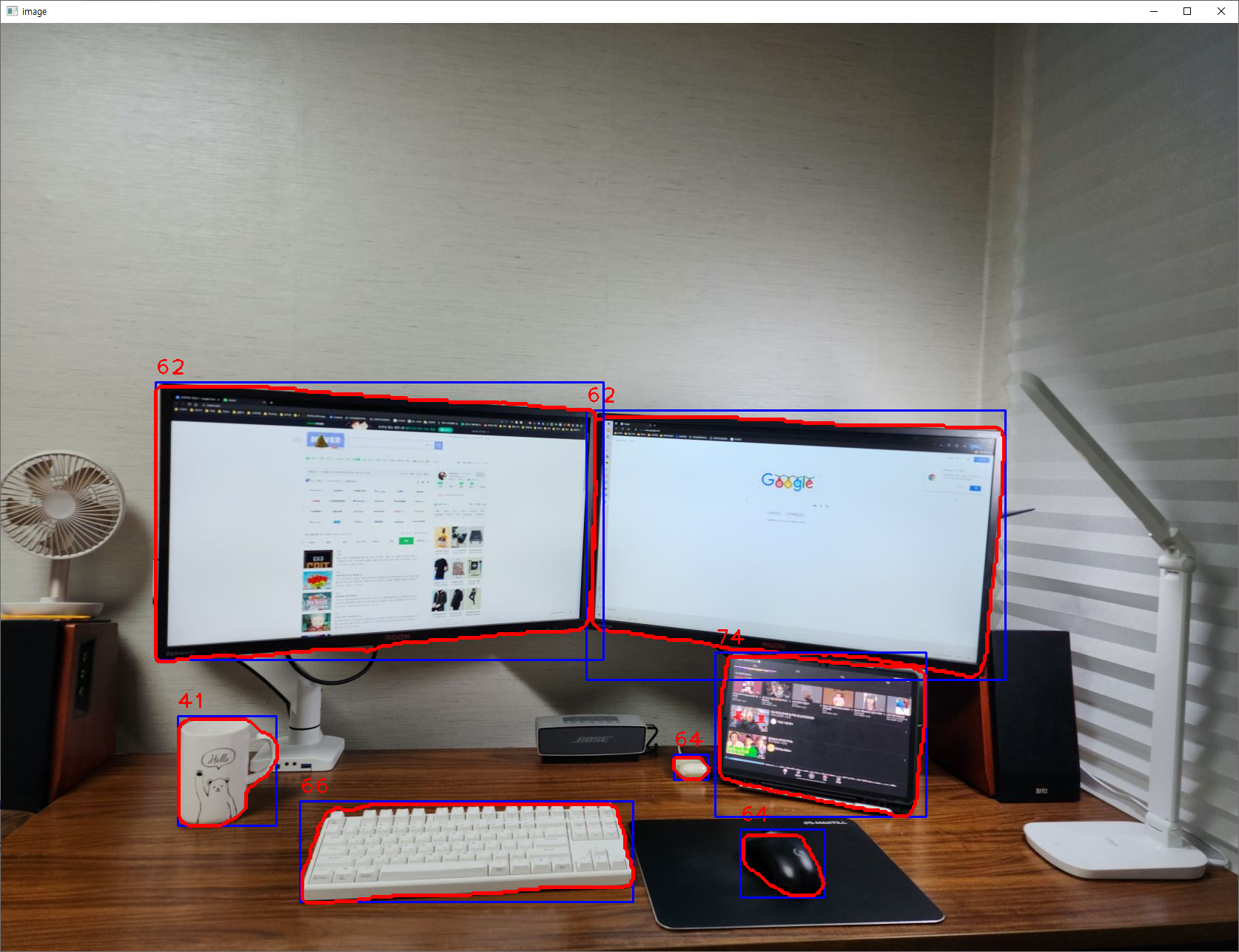
Ultralytics YOLOv8은Ultralytics 에서 개발한 YOLO(You Only Look Once) 객체 감지 및 이미지 분할 모델의 최신 버전입니다. YOLOv8은 이전 YOLO 버전의 성공을 바탕으로 새로운 기능과 개선 사항을 도입하여 성능과 유연성을 더욱 향상시키는 최첨단 SOTA(최신 기술) 모델입니다. https://docs.ultralytics.com/ YOLOv8 Docs Home Welcome to the Ultralytics YOLOv8 documentation landing page! Ultralytics YOLOv8 is the latest version of the YOLO (You Only Look Once) object detection and image segmen..